决策方面,更能够明白当下阶段应该做什么。今年已经开始有了一些 good sense ,希望明年能够继续保持和加强。
技术方面,能够更加严格而细致地把关技术方案,提前规避方案设计的不完善带来的风险。
沟通方面,加强倾听,同时让沟通更加达到目的。
成长方面,更加关注每一位成员的产出问题,及时发现成员在工作中的问题,并且能提出更高的要求。
除了管理方面的挑战,这一年中,我还深刻感受到了其他方面的一些压力和挑战。其中最大的一项挑战来自于协调目标的困难。当一个任务,一方坚持要做,一方坚持不做的时候,这时候项目的执行者就会置身于冲突之中。在这一年中,我也有过一段痛苦的迷茫期,不知道自己该做些什么。我开始阅读起一本关于如何做决策的书,来自桥水基金公司创始人 Ray Dalio 的《原则》。
玩了几天 Muse 后,我就已经把目前 Muse 所提供的现成能力都“榨干”了。后面就需要开始往更加困难的目标前进:真正识别意图。但如 Muse Direct 所述:
It is important to note that this raw data can be difficult to interpret and you may want to consider getting in touch with an experienced EEG Researcher for your project as we are unable to provide further support with the analysis and processing of the EEG data you collect.
ReferenceError: internalBinding is not defined at internal/util/inspect.js:31:15 at req_ (/Users/panweizhou/Documents/projects/hexo-blog/node_modules/natives/index.js:137:5) at require (/Users/panweizhou/Documents/projects/hexo-blog/node_modules/natives/index.js:110:12) at util.js:25:21 at req_ (/Users/panweizhou/Documents/projects/hexo-blog/node_modules/natives/index.js:137:5) at require (/Users/panweizhou/Documents/projects/hexo-blog/node_modules/natives/index.js:110:12) at fs.js:42:21 at req_ (/Users/panweizhou/Documents/projects/hexo-blog/node_modules/natives/index.js:137:5) at Object.req [as require] (/Users/panweizhou/Documents/projects/hexo-blog/node_modules/natives/index.js:54:10) at Object.<anonymous> (/Users/panweizhou/Documents/projects/hexo-blog/node_modules/graceful-fs/fs.js:1:37) npm ERR! code ELIFECYCLE npm ERR! errno 1 npm ERR! hexo@2.8.3 start: `hexo s` npm ERR! Exit status 1 npm ERR! npm ERR! Failed at the hexo@2.8.3 start script. npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
npm ERR! A complete log of this run can be found in: npm ERR! /Users/panweizhou/.npm/_logs/2020-01-19T04_49_41_873Z-debug.log (base) ➜ hexo-blog git:(master) ✗
if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--ip", default="127.0.0.1", help="The ip to listen on") parser.add_argument("--port", type=int, default=5000, help="The port to listen on") args = parser.parse_args()
server = osc_server.ThreadingOSCUDPServer( (args.ip, args.port), dispatcher) print("Serving on {}".format(server.server_address)) server.serve_forever()
玩了几天 Muse 后,我就已经把目前 Muse 所提供的现成能力都“榨干”了。后面就需要开始往更加困难的目标前进:真正识别意图。但如 Muse Direct 所述:
It is important to note that this raw data can be difficult to interpret and you may want to consider getting in touch with an experienced EEG Researcher for your project as we are unable to provide further support with the analysis and processing of the EEG data you collect.
Ajay Shanbhag, Aman Prabhu Kholkar, Saish Sawant, Allister Vicente, Sparsh Martires, and Supriya Patil. 2017. P300analysis using deep neural network. In 2017 International Conference on Energy, Communication, Data Analytics andSoComputing (ICECDS). IEEE, 3142–3147. ↩︎
Mingfei Liu, Wei Wu, Zhenghui Gu, Zhuliang Yu, FeiFei Qi, and Yuanqing Li. 2018. Deep learning based on BatchNormalization for P300 signal detection. Neurocomputing 275 (2018), 288–297 ↩︎
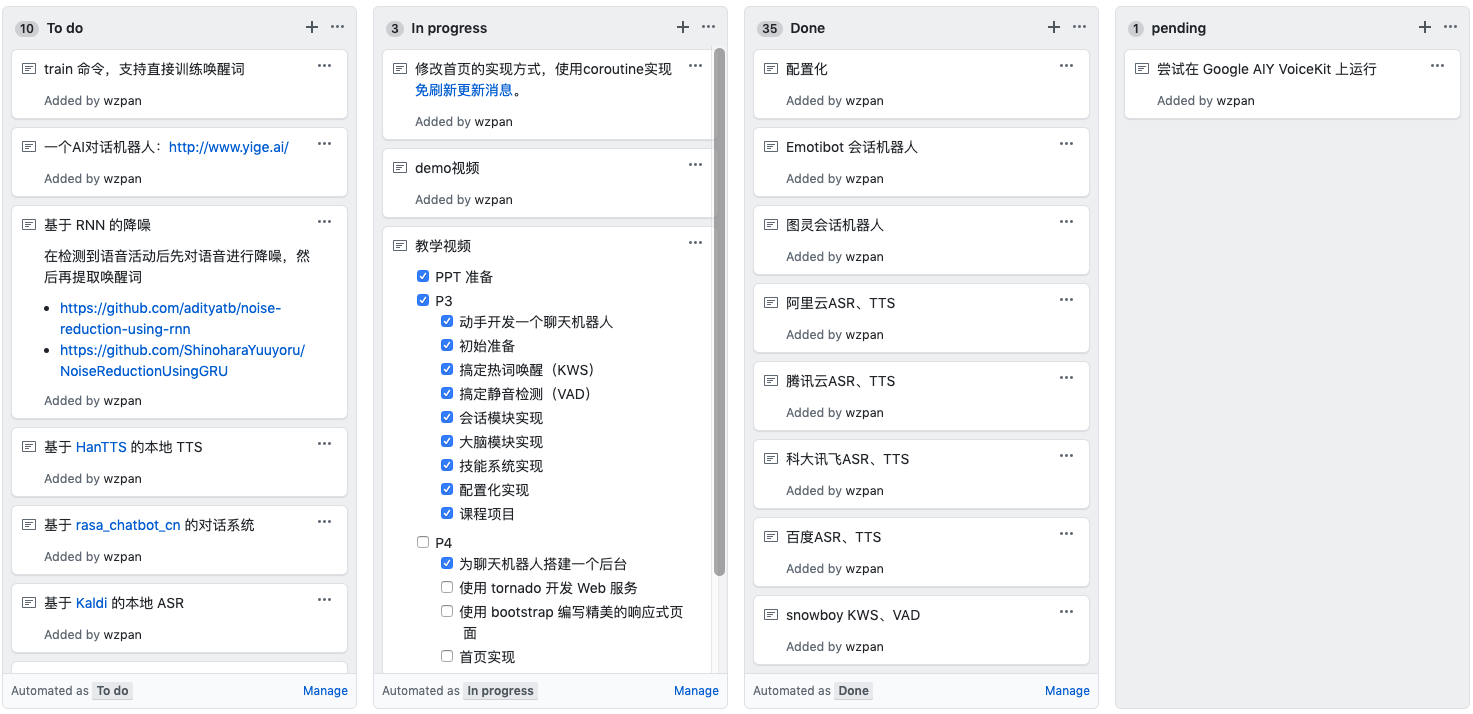
我把项目分成了 To do、In Progress、Done、Pending 几个状态。在规划第一个版本的时候,我就在 To do 栏中提了 10 个左右的需求。这使得我的项目可以朝着明确的目标演进。不过,在开发的时候,时常还会有一些新的想法冒出来,这时候我也会尽快写入需求池中。到真正发布 1.0 的时候,我已经完成了 21 个需求。
This is due to the acoustic distortion that results from the different microphones. If you record your voice with two different microphones (one on your laptop and the other on your Pi) and then play them (play t.wav), you will hear that they sound very differently (even though it is the same voice)!
了解到原因后,我在这个版本中去除了安装繁琐且中文识别较差的 PocketSphinx ,将 snowboy 作为主要的热词唤醒引擎。因为 snowboy 还提供了静音检测(VAD)的功能,所以我把原来 VAD 的代码全部去除,改为了直接使用 snowboy 的 VAD 。经过改写后,整个系统的稳定性和响应速度都有了质的提升。
再后来我发现还有一个 csrf_cookies ,可以用来防止跨站请求的问题。于是我很兴奋地加入了这个校验。但后面我发现这个跨站请求保护也只适用于站点本身的保护,因为 xsrf_cookies 的校验会在调用我们的接口实现方法前就完成,一旦加了这个校验后,其他客户端在调用 API 时也必须带上 csrf_cookies ,否则会直接抛出 '_xsrf' argument missing from POST 的错误。因此这个校验更适合用于纯 Web 站点,而不适合用于开放 API 的应用。
A boss uses people but leader develops people. A boss issues ultimatums but leader generates enthusiasm. A boss says “I” but leader says “we”. A boss takes credit but leader gives credit. A boss says “go” but leader says “Let’s go”. A boss make followers but leader makes leaders.
严格意义上对外授课并不能算工作本分内的事情。不过既然选择了教育这个行业,所以除了开发教育App之外,制作课程对外分享也就变成了对自己所处的这个大行业的一个积极探索和实践。Jerry 说 Age of Learning 公司在招聘的时候,会首先考察的就是这个人对教育这个行业有没有热情。我也非常认同将行业方向当作择业的第一标准。多参与行业内的不同形式的实践,反过来也能够提升我对这个行业的投入积极性和洞察能力。所以我也把授课列入“正经事”这个大分类里头。
Ukulele 也让我对吉他重拾了兴趣。我曾在大学期间买了一把吉他,学了一段时间爬格子后就已经兴致索然。之后又在一次调琴弦的时候因为方法不当把弦弄断了,于是这把琴就被我带回家扔起来了。国庆的时候回了一趟家,找出了这把尘封多年的吉他,大概摸了半个小时很快就可以上手弹唱了。唯一遇到的困难是 F 和弦依然是按不下去,但我认为并不是自己的方法问题,而是这把琴质量太差,品距太高导致加大了 F 和弦的难度。我已经开始种草 Taylor 114ce ,说不定等搬到新房子后就拔草。不过在剁手前,我应该会先去逛下琴行看看有没有更适合自己的定制琴。附图 3 像这种路边摊ukulele千万别买
说到买乐器这个话题,真的要相信“一分钱一分货”硬道理。不同价格的乐器,演奏效果的确有云泥之别。我的 Ukulele 是三年前 Allen 送我的 Rainie Poet S-30L,这把琴用桃花芯实木作为面板,音色饱满,琴头弦枕也很稳定,可以放好几个星期都不用调弦。弹久了之后,再去碰其他人的那种一两百块的 Ukulele ,就能明显感觉到劣质琴的廉价感——劣质琴因为用的是很差的面板,音色很单薄,拿在手上感觉很轻,而且面板和背侧板的衔接处往往都不会打磨,手臂放在上面会感觉很硌手。除此之外,劣质琴的和弦很不稳,放个一两天就又得重新调弦。用差的乐器绝对也会影响学习质量。所以我认为学习乐器并不存在所谓的“入门琴”的概念,要买就得买好一点的,这样才能真正的入门。当然,买什么价位的乐器需要量力而行,否则如果买来只是放着吃灰的话就浪费了。
因为马来西亚的华人比例很高,所以华人文化对大马的影响非常大。亚庇的菜市场上,一个中文说得不太麻利的卖菜小哥会唱《我们不一样》吸引你去买他的海鲜。在仙本那的路口,一群黝黑的马来人会围在一起玩《王者荣耀》。除此之外,英语在马来西亚是官方通行语言,遇到不会讲中文的印度人和马来人,用英语都能交流。不像在泰国,有时候会遇到中文和英文都不好的司机,只能靠 body language 和翻译软件交流。
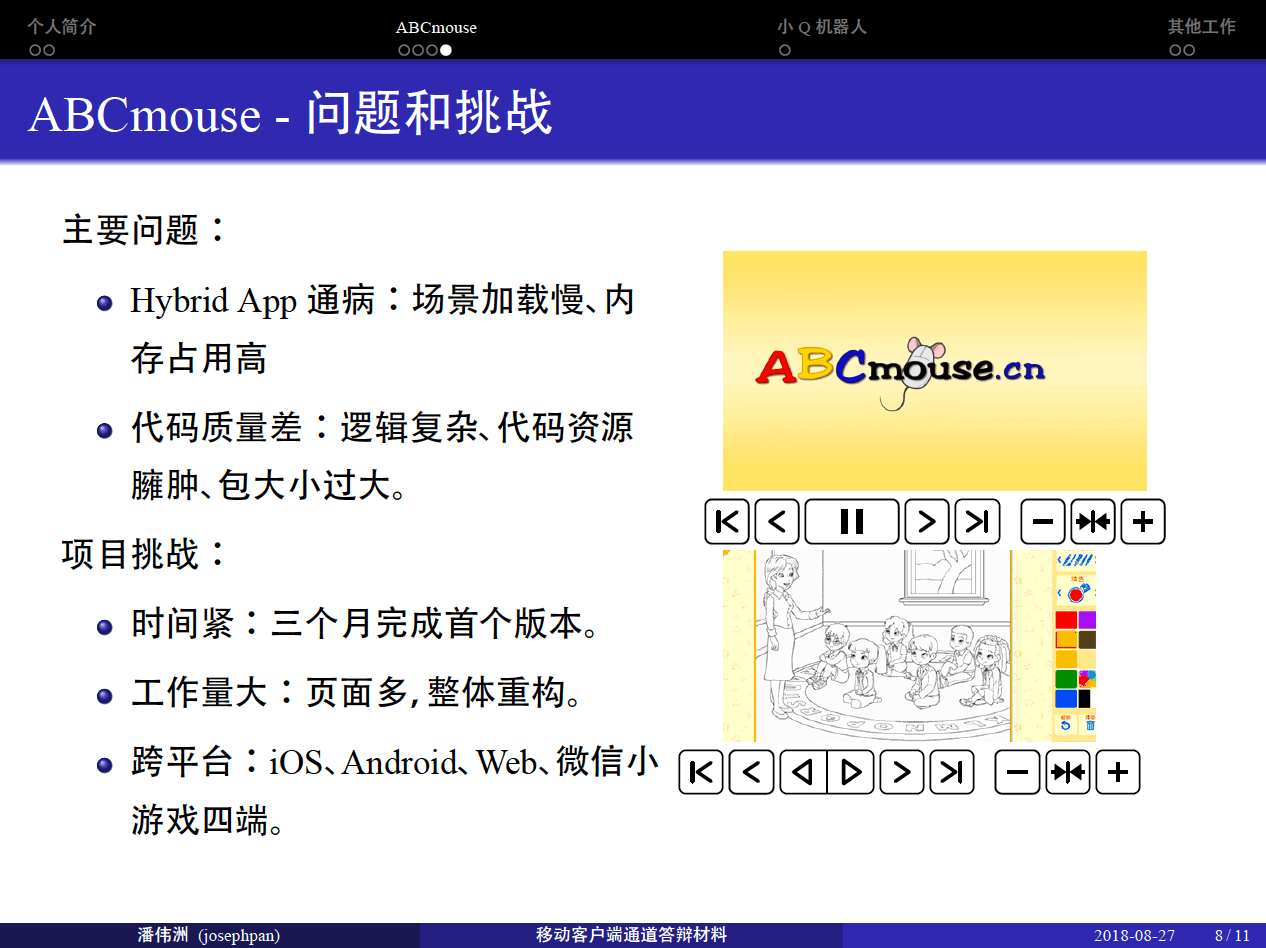
洛杉矶之行严格上说其实是出差,主要的目的是跟 ABCmouse 的母公司 Age of Learning 公司商讨明年的运营计划以及技术交流。所以白天的时间我基本都是在 Age of Learning 的公司里头待着,给 Age of Learning 的 China team 讲关于 code standard、spine animation dynamically loading、input event system 等技术相关的东西。附图 4 在 Age of Learning 的临时工位,桌子是可以上下移动的。China team 非常体贴地专门为我申请了一台外接显示器。
Age of Learning 的办公大楼在 Glendale 市,离 the Americana at Brand 很近,所以有一天晚上我们去那里溜达了一圈并和 Age of Learning 的老板们聚了个餐。虽然距离圣诞还有两周的时间,但商城已经被打扮得非常有圣诞气氛,在路上 Jerry 告诉我们 ABCmouse 里的商城的设计灵感就取自 Americana ,顿时有种走进了 ABCmouse 世界里的奇妙感。
完成了我们在 Age of Learning 里的 agenda 后,Neal 带着我和 Yul 去他在 Irvine 的房子玩,我也总算见识到了在美国住 house 有多爽:Neal 的房子总面积有两千尺,两层楼,总价格却只有我的房子的价格的一倍。相比之下,我的房子只是个六十平米的两房 department 。不过,在美国有钱的人喜欢住郊区,开车到上班的地方普遍要一两个小时。如果按这个距离算的话,到惠州、东莞买个 house 好像也可以达到类似的目的,但缺点就是学区不好。
尔湾的小区
在 Neal 家住了一晚后,和 Age of Learning 的小伙伴们一起去了趟 Disneyland 。沾了 Age of Learning 的光,除了过了机动游戏的瘾之外,我们在 Disneyland club 33 吃了顿大餐,这是一个隐藏在 Disneyland 里的西餐馆,只有会员才能进入。据说,想成为 club 33 的成员,不仅得交得起昂贵的会员费(坊间传言入会费为 2.5 万美元,每年年费为 1.2 万美元),而且等候入会的名单已经安排到十多年后了。说白了这就是一个饥饿营销的典型成功案例。
当然在 Disneyland 的重头戏还是那些机动游戏。但因为时差的原因,我到了下午依然是困得睁不开眼。所以我就一边排队一边站着打瞌睡,然后再利用各种 roller coaster 或者其他刺激项目提神,效果不错 😹 。附图 5 Golden State Free Way,这里是电影《爱乐之城》第一段公路舞蹈《Another Day of Sun》的取景地。
回国的最后一天,Jerry 开车带我们在 LA 兜了一圈。我们沿着 Golden State Free Way 开去了一个叫做 Sunset Ranch 的农场,近距离打卡拍下了 HOLLYWOOD 的标志。
LA 的 landmark 之一:HOLLYWOOD 标志
总的来说这次的 LA 之行最大的收获在于拓宽了我的眼界,了解了美国人的生活和工作方式,也让我设身处地的思考如果我在这边生活能不能适应下来。从目前来看,美国的生活方式其实挺适合我这种晚上不爱出门闲逛的人。而交流方面,虽然我的口语并没有特别厉害,但理解和用简单的英文回答是没有问题的。比如,在打 Uber 的时候我能够一路跟一个埃及的司机 Hishan 交谈彼此国家的文化、交通、政治,还跟他分享了来中国旅游的建议。当然我目前还没有感受到移民工作的必要性,一方面我还没有离开目前团队的打算;另一方面 H1B 的限制太大,在拿绿卡前一直不能回家见父母其实是一件很难熬的事情。
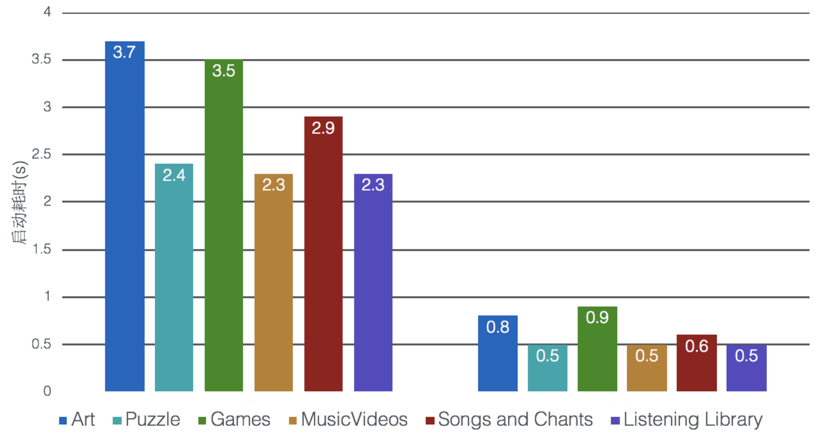
游戏
今年购买的游戏
我喜欢的游戏类型比较窄,主要爱玩 PC 上的角色扮演类游戏,而且我并不会把玩游戏作为平时的固定娱乐项目,只是突然心血来潮了就玩一下游戏,等玩上一段时间后,感到满足了就可以很长时间不玩。
月亮与六便士:讲述了查尔斯·斯朱兰人到中年放弃了自己让人羡慕的银行家的事业以及美满的家庭选择去当画家的离奇一生。从世俗的眼光看来,查尔斯是一个极其让人讨厌的奇葩。但他丝毫没有受到外界的指责的影响,依然执着地追求自己的理想,甚至不惜为此忍受饥寒交迫的生活。从这个角度来看,他又是伟大的。想起了漫威之父 Stan Lee 对年轻人的告诫:
I think whatever you do, you should do what you most want to do.
所以我有时候会冒出用技术手段来帮助恋爱的念头,比如智能 match 合适人选,用 NLP 分析 IM 里对方的应答,提供化解尬聊的话题建议,或是自动根据双方喜好预定餐馆和菜式。无奈当前的 NLP 技术还不够成熟,而且这样的话似乎双方并不是真正地在交往,而是变成由机器人来确定恋爱关系——人在这场恋爱中反而成了傀儡了。就像《黑镜》第四季第 5 集《Hang the DJ》中的桥段,过度依赖技术来培养爱情其实是很容易弄巧成拙的。
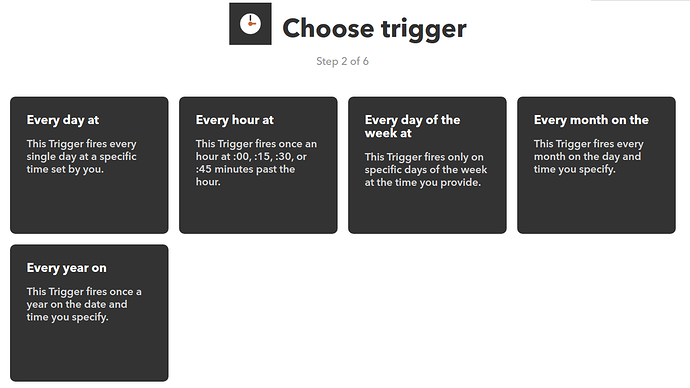
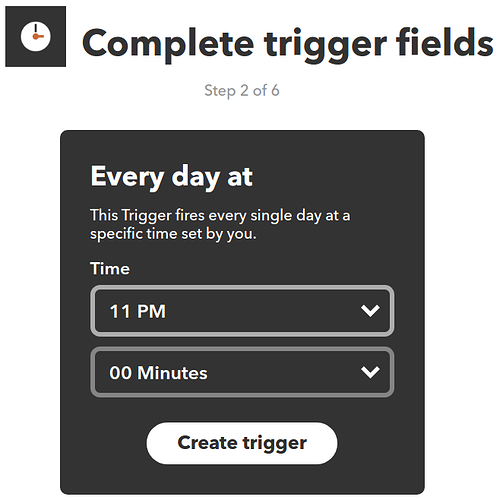
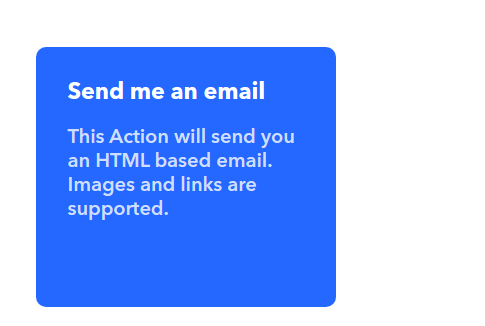
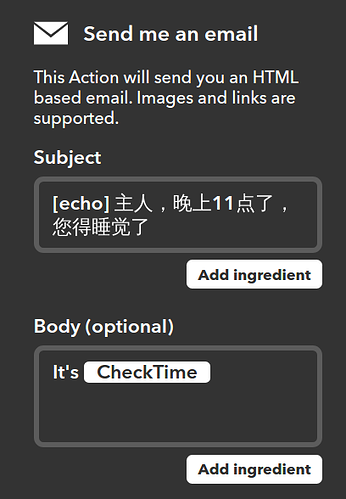
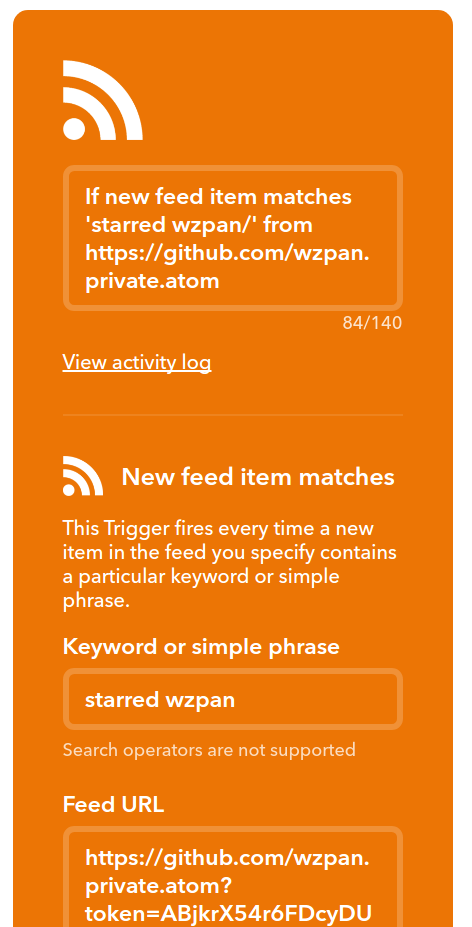
IFTTT 是一个被称为 “网络自动化神器” 的创新型互联网服务,它非常实用而且完全免费。它的全称是 If this then that,意思是“如果这样,那么就那样”。简单地讲,IFTTT 的作用就是,如果「这个」网络服务满足条件,那么就自动触发「那个」网络服务去执行一个动作。而条件和动作都是可以由用户自己去根据自身需求设置的。IFTTT 能将前后这两个不同的网络服务神奇般地连通来实现各种各样的功能,并且为你不间断地工作。
在百度的期间我最大的收获在于对潜在的需求有着非常灵敏的嗅觉。当时的平安才刚面临技术转型,一些内部系统难免有不尽完善的地方,这对于来自 BAT 这类有着完善的内部系统的公司的同事而言很难适应。和大多数花时间吐槽环境的同事不同,我觉得这是一个好机会,这代表内部就有很多需求。所以,利用空余时间,我也做了一些“支线任务”,提高团队的效率。
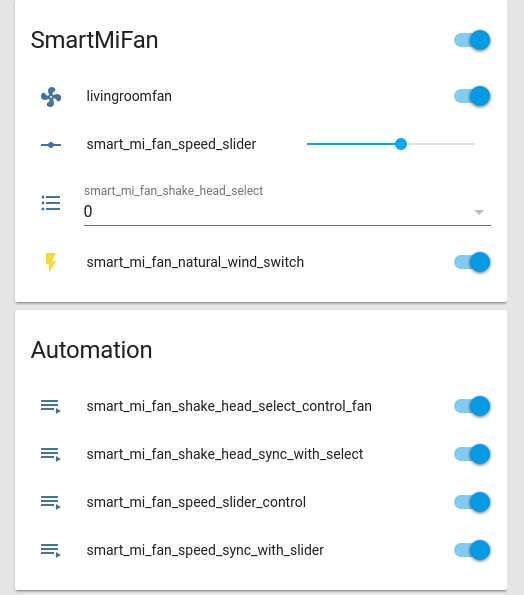
如今很多智能音箱除了用来听歌对话之外,还扮演了家庭中的一个控制中心的角色。不过,由于各家采用的接入协议有所区别,A 家的智能家电并不见得能得到 B 家的智能音箱的支持。而由于叮当是开源的项目,对其进行定制,接入控制家电所需的协议,从而实现声控大部分的智能家电是完全可能的。今天我就分享一下如何用叮当控制智米电风扇。
之后我找到了 isso 项目,它是一个 Python 实现的开源评论服务。这个服务需要搭建在自己的服务器上。官方的简介简明扼要:“a Disqus alternative”。出于对 Python 的好感,我把站点的评论功能迁移到了 isso 。然而,我对 isso 也并不是很满意。首先它的功能其实也非常弱,不支持 Markdown 语法,不支持 Gravatar 头像,也没有一个像样的管理后台,搭建和配置的过程也比较费时,远达不到开箱即用的程度。再加上 isso 需要服务器运营,为了一个评论系统而去购买服务器确实太奢侈了。用了几个月后,我又萌生了换掉它的念头。
要实现天气预报功能,少不了要了解一下天气 API 。通过搜索,我找到了一款免费的天气 API —— 心知天气 。心知天气提供了天气、空气质量、生活指数等多种数据信息。其中逐日天气预报是免费的,可以利用来实现天气预报查询插件。
选择心知天气的另一个理由是他们的 API 文档非常详细,还提供了多种语言的 demo (连 common-lisp 都有,点个赞! )。下面是官方提供的一个 Python 版的示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
import requests from utils.const_value import API, KEY, UNIT, LANGUAGE from utils.helper import getLocation
deffetchWeather(location): result = requests.get(API, params={ 'key': KEY, 'location': location, 'language': LANGUAGE, 'unit': UNIT }, timeout=1) return result.text
if __name__ == '__main__': location = getLocation() result = fetchWeather(location) print(result)
其中,API 是 API 的地址,逐日天气预报的 API 地址是 https://api.seniverse.com/v3/weather/daily.json ;KEY 则是心知天气的 API 密钥,每个注册账户都可以得到一个密钥;location 是城市名,例如深圳就是 深圳 或者 shenzhen;而 language 和 unit 分别表示语言和单位,由于是可选参数,这里不做详细介绍。有兴趣的朋友请阅读官方文档。
整段代码也没有什么特别好说的:先是定义了一个 fetchWeather 函数,该函数使用 requests 模块发起 API 请求,请求超时设置为 1 秒。之后调用这个函数并打印返回的结果。
defhandle(text, mic, profile, wxbot=None): """ Responds to user-input, typically speech text Arguments: text -- user-input, typically transcribed speech mic -- used to interact with the user (for both input and output) profile -- contains information related to the user (e.g., phone number) wxbot -- wechat bot instance """ pass
defisValid(text): """ Returns True if the input is related to weather. Arguments: text -- user-input, typically transcribed speech """ pass
defisValid(text): """ Returns True if the input is related to weather. Arguments: text -- user-input, typically transcribed speech """ returnu"天气"in text
defhandle(text, mic, profile, wxbot=None): """ Responds to user-input, typically speech text Arguments: text -- user-input, typically transcribed speech mic -- used to interact with the user (for both input and output) profile -- contains information related to the user (e.g., phone number) wxbot -- wechat bot instance """ pass
defhandle(text, mic, profile, wxbot=None): """ Responds to user-input, typically speech text Arguments: text -- user-input, typically transcribed speech mic -- used to interact with the user (for both input and output) profile -- contains information related to the user (e.g., phone number) wxbot -- wechat bot instance """ logger = logging.getLogger(__name__) # get config if 'weather' not in profile or \ not profile[SLUG].has_key('key') or \ not profile[SLUG].has_key('location'): mic.say('天气插件配置有误,插件使用失败') return key = profile[SLUG]['key'] location = profile[SLUG]['location'] WEATHER_API = 'https://api.seniverse.com/v3/weather/daily.json' try: weather = fetch_weather(WEATHER_API, key, location) logger.debug("Weather report: ", weather) if weather.has_key('results'): daily = weather['results'][0]['daily'] day_text = [u'今天', u'明天', u'后天'] responds = u'%s天气:' % location for day inrange(len(day_text)): responds += u'%s:%s,%s到%s摄氏度。' % (day_text[day], daily[day]['text_day'], daily[day]['low'], daily[day]['high']) mic.say(responds) else: mic.say('抱歉,我获取不到天气数据,请稍后再试') except Exception, e: logger.error(e) mic.say('抱歉,我获取不到天气数据,请稍后再试')
basepath=$(cd `dirname $0`; pwd) command -v git-lfs >/dev/null 2>&1 || { echo >&2 "\nThis repository is configured for Git LFS but 'git-lfs' was not found on your path. If you no longer wish to use Git LFS, remove this hook by deleting .git/hooks/pre-push.\n"; exit 2; } git lfs pre-push "$@" && $basepath/pre-push-custom
>>> a = np.matrix('1 2;4 3') >>> print np.linalg.eigvals(a) [-1.5.]
前面说了变换矩阵必须是方阵,所以如果用在其他形状的矩阵上就会抛出 LinAlgError 错误:
1 2 3 4 5 6 7 8 9
>>> b = np.matrix('1 2 3;4 3 1') >>> print np.linalg.eigvals(b) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/local/lib/python2.7/dist-packages/numpy/linalg/linalg.py", line 902, in eigvals _assertNdSquareness(a) File "/usr/local/lib/python2.7/dist-packages/numpy/linalg/linalg.py", line 212, in _assertNdSquareness raise LinAlgError('Last 2 dimensions of the array must be square') numpy.linalg.linalg.LinAlgError: Last 2 dimensions of the array must be square
终于完成了线性代数的系列。作为保研党,真正系统学习线性代数也就是在大一的时期,然后大学四年也没怎么用到数学,渐渐地就忘得差不多了。后来读研的时候虽然也用到些线性代数,但都是用到啥补啥,跟其他考研上来的同学比起来,心里面总是缺少一点底气。在中科院实习结束的时候,陈宝权老师和 Andrei 一直劝我读博,最后我婉拒了,其中一个原因也和这个“没底气”有关吧。而今我也工作快两年了,虽然还是没有读博的念头,但还是希望把数学捡起来,让自己也有底气一些。

 附图 1 “同心战役”纪念企鹅
附图 1 “同心战役”纪念企鹅




 附图 1 陈振平老师的《登上成功管理的舞台》课后留念。
附图 1 陈振平老师的《登上成功管理的舞台》课后留念。
 附图 2 在大梅沙参加的潜龙培训合影。
附图 2 在大梅沙参加的潜龙培训合影。
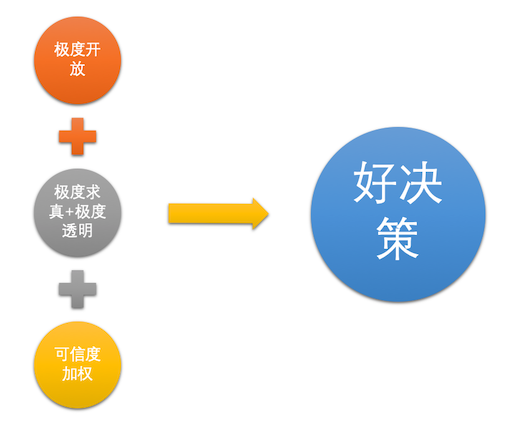
 附图 3 OKR = 目标+关键结果
附图 3 OKR = 目标+关键结果
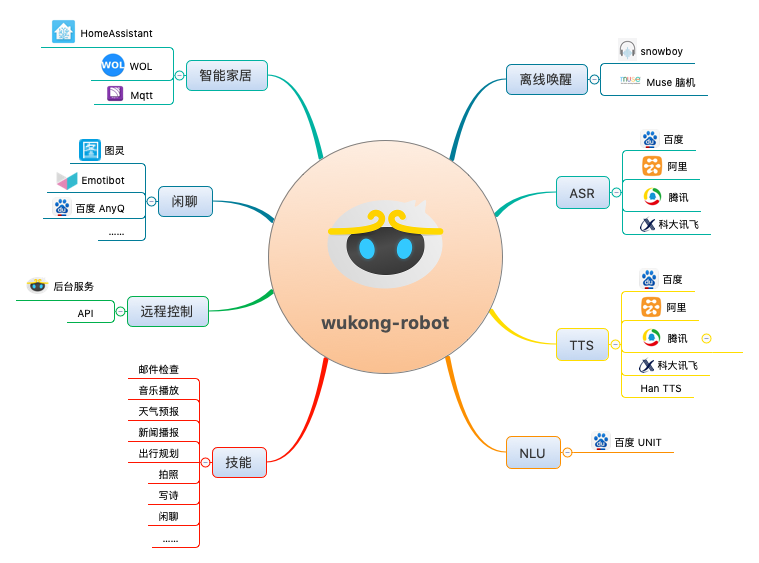
 附图 4 ycy-robot ,是我一时技痒参加的杨超越编程大赛的参赛作品。基于 wukong-robot 定制了一些月芽专属技能,以及配套了佩奇粉后台管理端皮肤和“超超越越”唤醒词。
附图 4 ycy-robot ,是我一时技痒参加的杨超越编程大赛的参赛作品。基于 wukong-robot 定制了一些月芽专属技能,以及配套了佩奇粉后台管理端皮肤和“超超越越”唤醒词。

 附图 5 《未来简史》里认为未来人来三大命题是“长生不死”、“幸福快乐”、“化身为神”。
附图 5 《未来简史》里认为未来人来三大命题是“长生不死”、“幸福快乐”、“化身为神”。


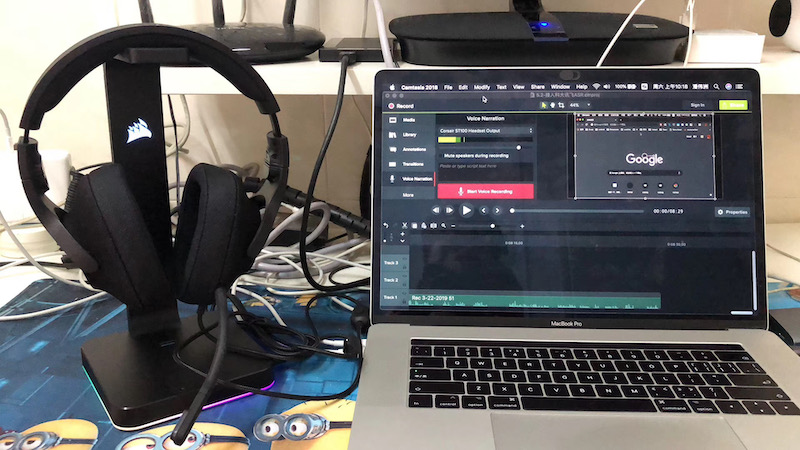 附图 6 为了更好的录音质量,下血本买了套罗技G433降噪耳麦+海盗船声卡耳机架。
附图 6 为了更好的录音质量,下血本买了套罗技G433降噪耳麦+海盗船声卡耳机架。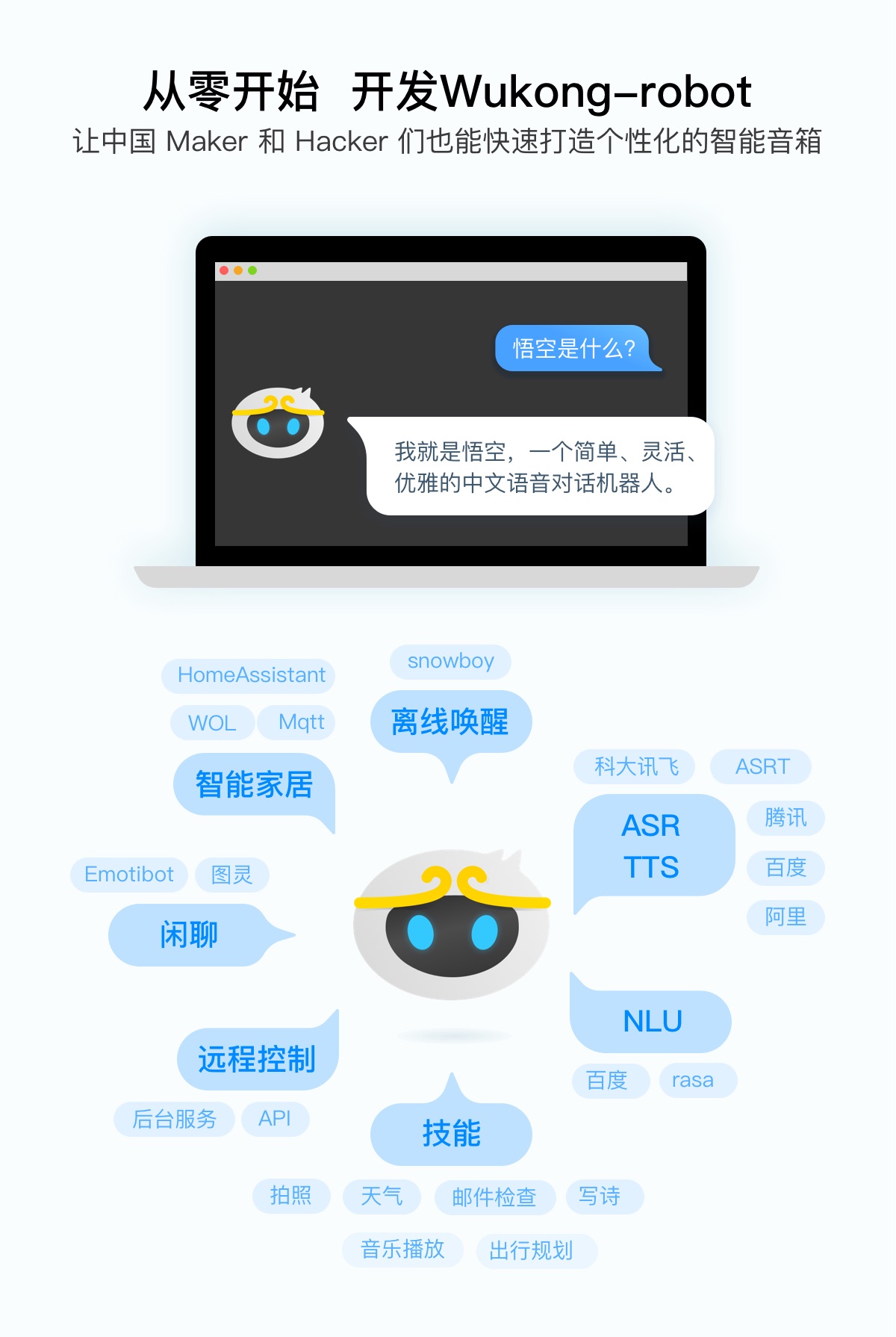
 附图 7 年底的时候腾讯课堂送来的纪念礼物
附图 7 年底的时候腾讯课堂送来的纪念礼物
 附图 8 群晖DS218+
附图 8 群晖DS218+





 附图 8 恰逢软件自由日,在岛上穿件节日T恤做个纪念。
附图 8 恰逢软件自由日,在岛上穿件节日T恤做个纪念。












 附图 9 在《古剑奇谭三》也有类似的牌类游戏元素,应该就是借鉴了《巫师 3》中的设计。
附图 9 在《古剑奇谭三》也有类似的牌类游戏元素,应该就是借鉴了《巫师 3》中的设计。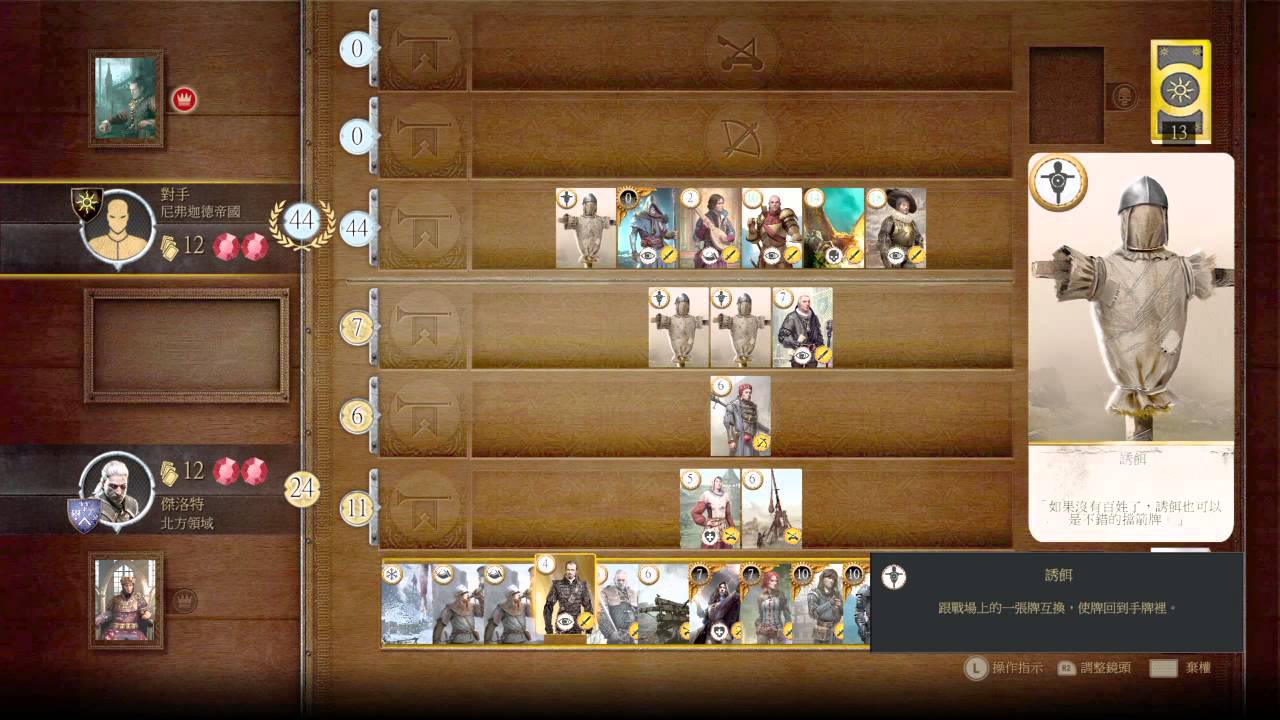

 附图 10 2015 版《无人生还》电视剧同样非常精彩
附图 10 2015 版《无人生还》电视剧同样非常精彩
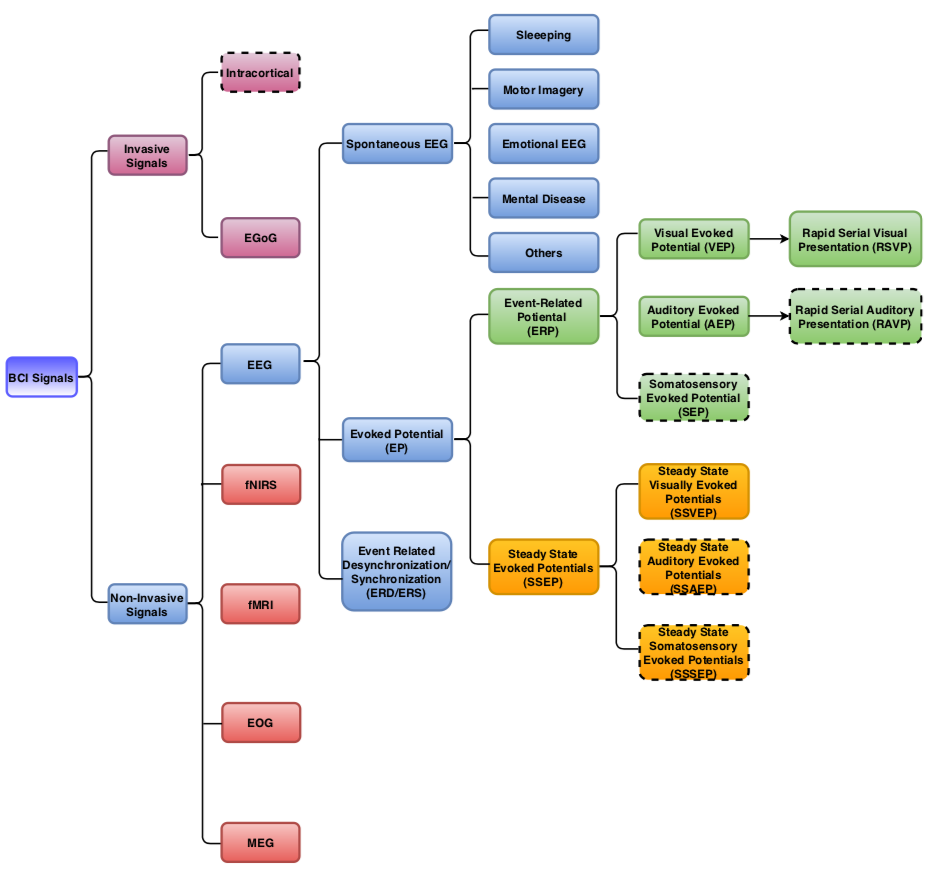
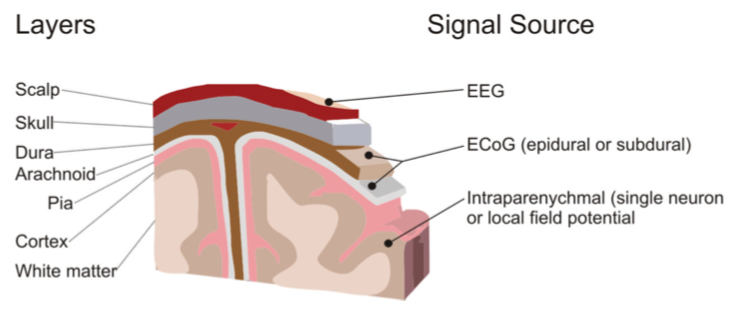
 附图 1 最近 Elon Musk 所带领提出的 Neuralink 技术也是一种侵入式的方法,其亮点在于通过一套称为“neural dust”的微型机器人来实现植入柔性电极。这套方法解决了以上两个挑战,值得后续关注。不过该技术目前最大的争议在于电极的植入位置无法同时覆盖全脑,且非消费级。
附图 1 最近 Elon Musk 所带领提出的 Neuralink 技术也是一种侵入式的方法,其亮点在于通过一套称为“neural dust”的微型机器人来实现植入柔性电极。这套方法解决了以上两个挑战,值得后续关注。不过该技术目前最大的争议在于电极的植入位置无法同时覆盖全脑,且非消费级。

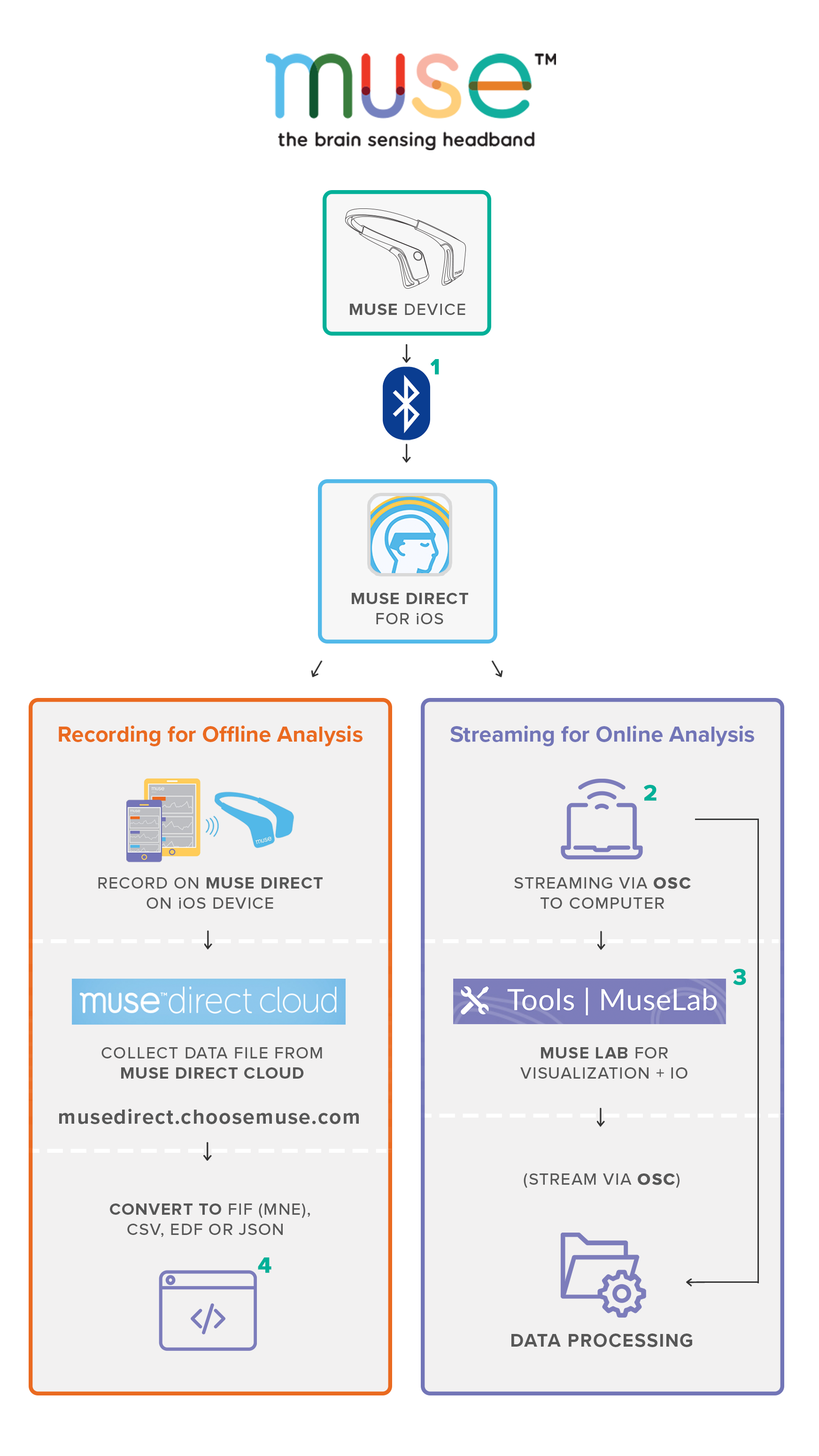
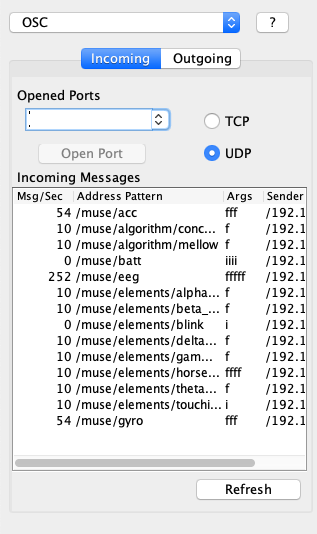
 即可开启 OSC 传输。
即可开启 OSC 传输。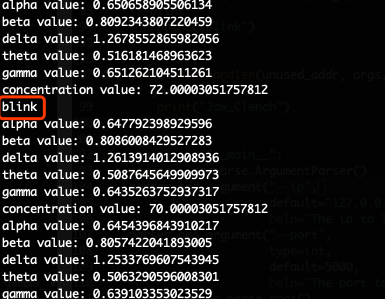









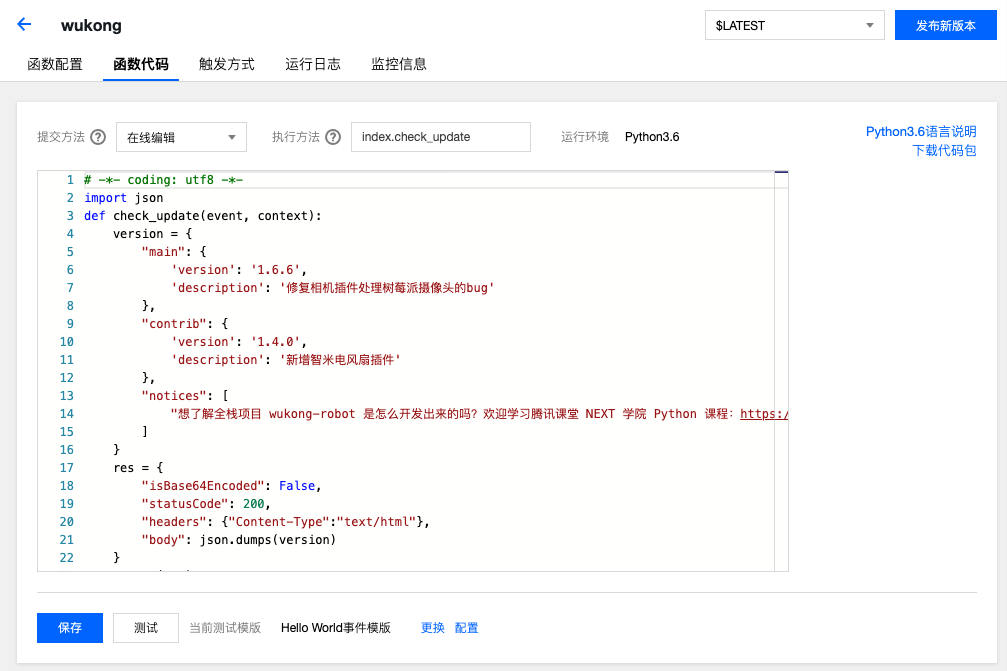


 附图 1 小黑屋时期的工位。虽然通风不好,但窗外的风景很好。
附图 1 小黑屋时期的工位。虽然通风不好,但窗外的风景很好。













 附图 2 工位上的三块键盘
附图 2 工位上的三块键盘

 附图 3 像这种路边摊ukulele千万别买
附图 3 像这种路边摊ukulele千万别买
















 附图 4 在 Age of Learning 的临时工位,桌子是可以上下移动的。China team 非常体贴地专门为我申请了一台外接显示器。
附图 4 在 Age of Learning 的临时工位,桌子是可以上下移动的。China team 非常体贴地专门为我申请了一台外接显示器。





 附图 5 Golden State Free Way,这里是电影《爱乐之城》第一段公路舞蹈《Another Day of Sun》的取景地。
附图 5 Golden State Free Way,这里是电影《爱乐之城》第一段公路舞蹈《Another Day of Sun》的取景地。









 附图 6 网播节目《一本好书》
附图 6 网播节目《一本好书》







 附图 1 现场观众
附图 1 现场观众
 附图 2 Apollo GraphQL的开发者 Sashko Stuballo 也来了
附图 2 Apollo GraphQL的开发者 Sashko Stuballo 也来了
 附图 3 在GMTC上遇到很多老朋友
附图 3 在GMTC上遇到很多老朋友 附图 4 新认识的一帮来自腾讯、Facebook、Twitter、UC、搜狗的小伙伴。我们开玩笑说互联网社交圈快凑齐了。学会一个新词儿,叫做“局气”。
附图 4 新认识的一帮来自腾讯、Facebook、Twitter、UC、搜狗的小伙伴。我们开玩笑说互联网社交圈快凑齐了。学会一个新词儿,叫做“局气”。


 附图 5 夜色中的水立方
附图 5 夜色中的水立方
 附图 6 颐和园摆渡
附图 6 颐和园摆渡

 附图 7 排云门前的石狮子
附图 7 排云门前的石狮子



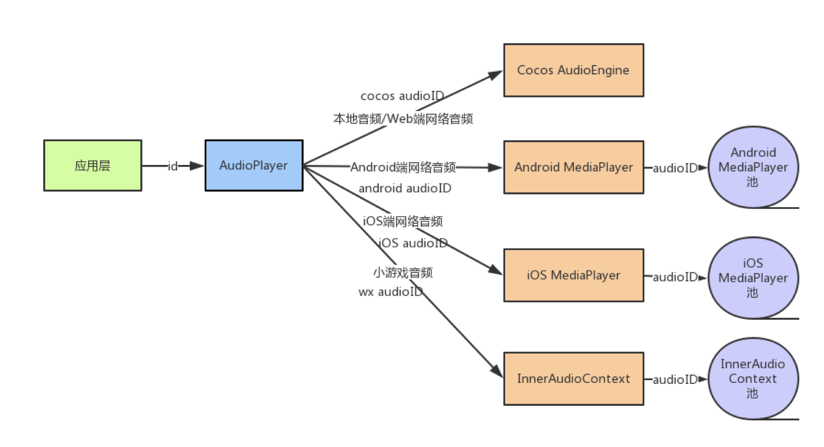
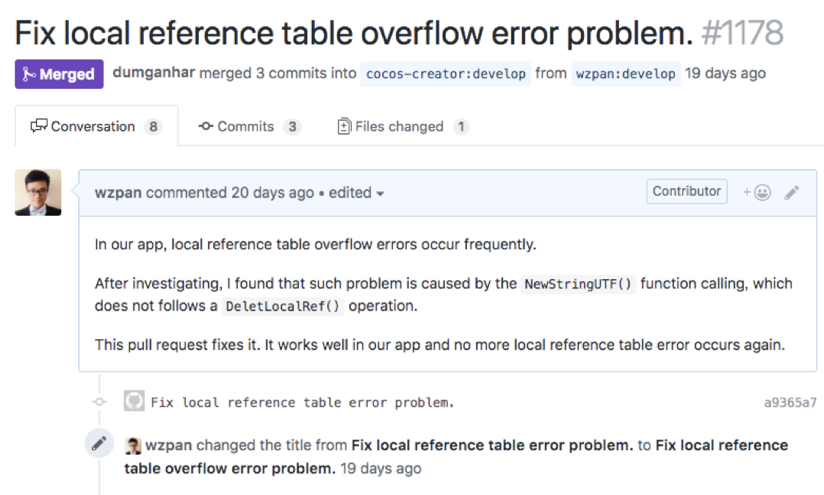
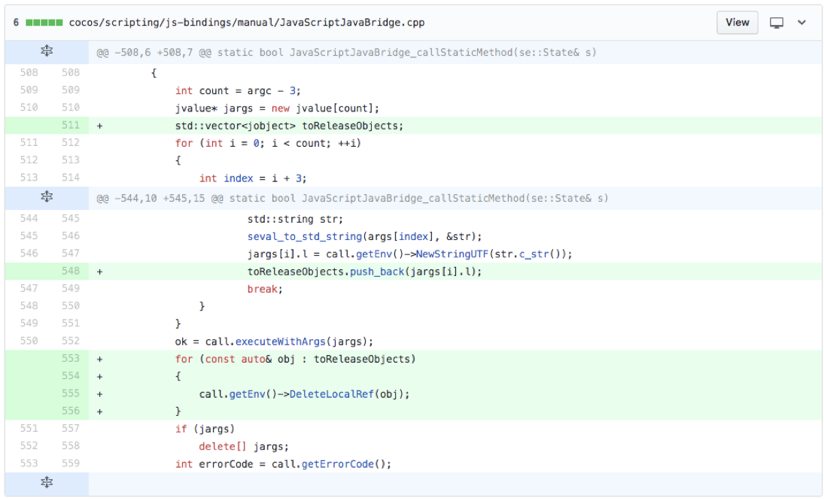
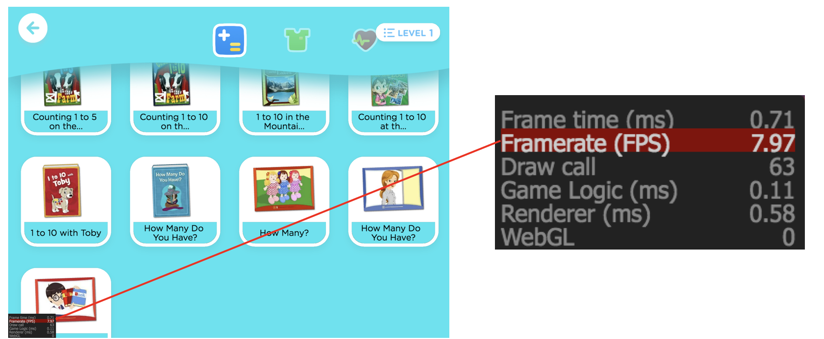








 ]]>
]]>






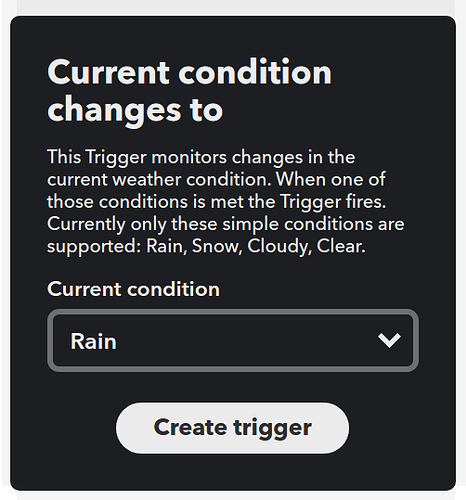

 附图 1 这两年拿过的各种奖杯奖牌
附图 1 这两年拿过的各种奖杯奖牌


 附图 2 我和我的Ukulele
附图 2 我和我的Ukulele 附图 3 由于 Git 的分享做的比较好,教师节的时候我被评上了公司的“十佳讲师”。收获小卡片一张。
附图 3 由于 Git 的分享做的比较好,教师节的时候我被评上了公司的“十佳讲师”。收获小卡片一张。

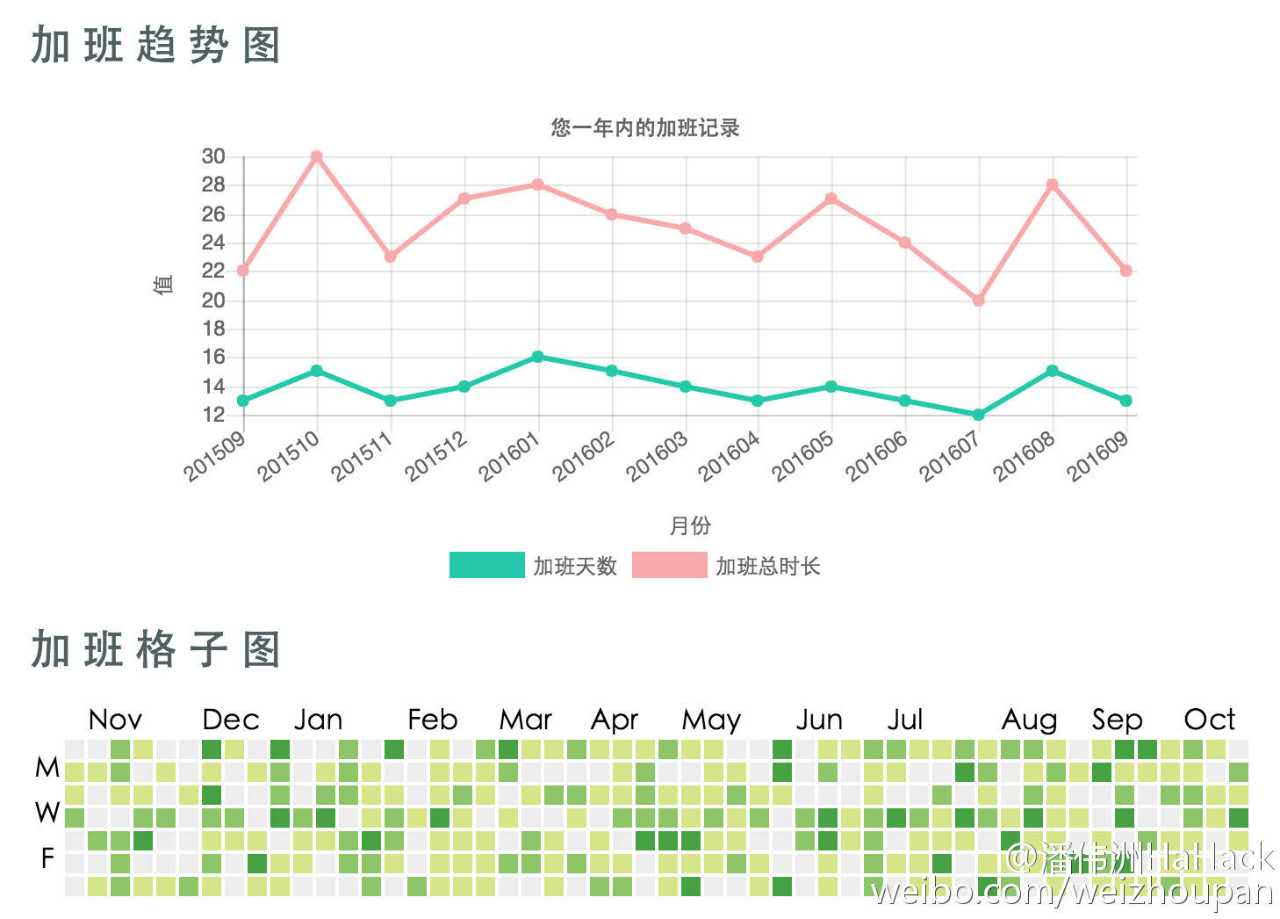
 附图 4 年会电子琴弹唱
附图 4 年会电子琴弹唱 附图 5 顺手给课程提了几个建议和bug,收到了 Udacity 寄来的小礼物。
附图 5 顺手给课程提了几个建议和bug,收到了 Udacity 寄来的小礼物。